1. Kubernetes是什么?
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态,其服务、支持和工具的使用范围相当广泛。 Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。k8s 这个缩写是因为 k 和 s 之间有八个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目。 Kubernetes 建立在Google 大规模运行生产工作负载十几年经验的基础上, 结合了社区中最优秀的想法和实践。
时光回溯
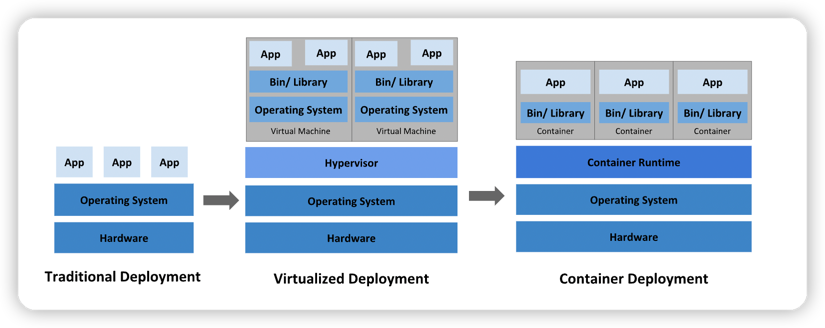
传统部署时代:
早期,各机构是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程式资源利用率不高时,剩余资源无法被分配给其他应用程式, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可伸缩性,以及降低硬件成本等等的好处。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统(OS)。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来。下面列出的是容器的一些好处:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
为什么需要 Kubernetes,它能做什么?
容器是打包和运行应用程序的好方式。在生产环境中, 你需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则你需要启动另一个容器。 如果此行为交由给系统处理,是不是会更容易一些?
这就是 Kubernetes 要来做的事情! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
Kubernetes 为你提供:
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来曝露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来为容器分配资源。
自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
2. 为什么是Kubernetes?
可以参考这篇文章从容器到容器云:谈谈Kubernetes的本质
3. Kubernetes 核心概念和术语
3.1 Master
Kubernetes 里的 Master 指的是集群控制节点,每个 Kubernetes 集群里需要有一个 Master 节点来负责整个集群的管理和控制, 基本上 Kubernetes 所有的控制命令都是发给它,它来负责具体的执行过程,我们后面所有执行的命令基本都是在 Master 节点上运行的。 Master节点通常会占据一个独立的 X86 服务器(或者一个虚拟机),一个主要的原因是它太重要了,它是整个集群的“首脑”,如果它宕机或者不可用,那么我们所有的控制命令都将失效。
Master 节点上运行着以下一组关键进程。
- Kubernetes API Server(kube-apiserver),提供了HTTP Rest 接口的关键服务进程,是
- Kubernetes 里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。
- Kubernetes Controller Manager(kube-controller-manager),Kubernetes 里所有资源对象的自动化控制中心,可以理解为资源对象的”大总管”。
- Kubernetes Scheduler(kube-scheduler),负责资源调度( Pod 调度)的进程,相当于公交公司的“调度室”。
其实 Master 节点上往往还启动了一个 etcd Server 进程,因为 Kubernetes 里的所有资源对象的数据全部是保存在 etcd 中的。
3.2 Node
除了 Master,Kubernetes 集群中的其他机器被称为 Node 节点,在较早的版本中也被称为 Minion。与 Master 一样, Node 节点可以是一台物理主机,也可以是一台虚拟机。Node 节点才是 Kubernetes 集群中的工作负载节点, 每个 Node 都会被 Master 分配一些工作负载(Docker容器),当某个 Node 宕机时,其上的工作负载会被Master自动转移到其他节点上去。
每个 Node 节点上都运行着以下一组关键进程。
- kubelet∶ 负责 Pod 对应的容器的创建、启停等任务,同时与 Master 节点密切协作,实现集群管理的基本功能。
- kube-proxy∶实现 Kubernetes Service 的通信与负载均衡机制的重要组件。
- Docker Engine(docker)∶Docker 引擎,负责本机的容器创建和管理工作。
Node 节点可以在运行期间动态增加到 Kubernetes 集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程, 在默认情况下 kubelet 会向 Master 注册自己,这也是Kubernetes 推荐的 Node 管理方式。一旦Node被纳入集群管理范围, kubelet 进程就会定时向 Master 节点汇报自身的情报,例如操作系统、Docker 版本、机器的 CPU 和内存情况, 以及之前有哪些 Pod 在运行等,这样 Master 可以获知每个 Node 的资源使用情况,并实现高效均衡的资源调度策略。 而某个 Node 超过指定时间不上报信息时,会被 Master 判定为“失联”,Node 的状态被标记为不可用(Not Ready),随后 Master 会触发”工作负载大转移”的自动流程。
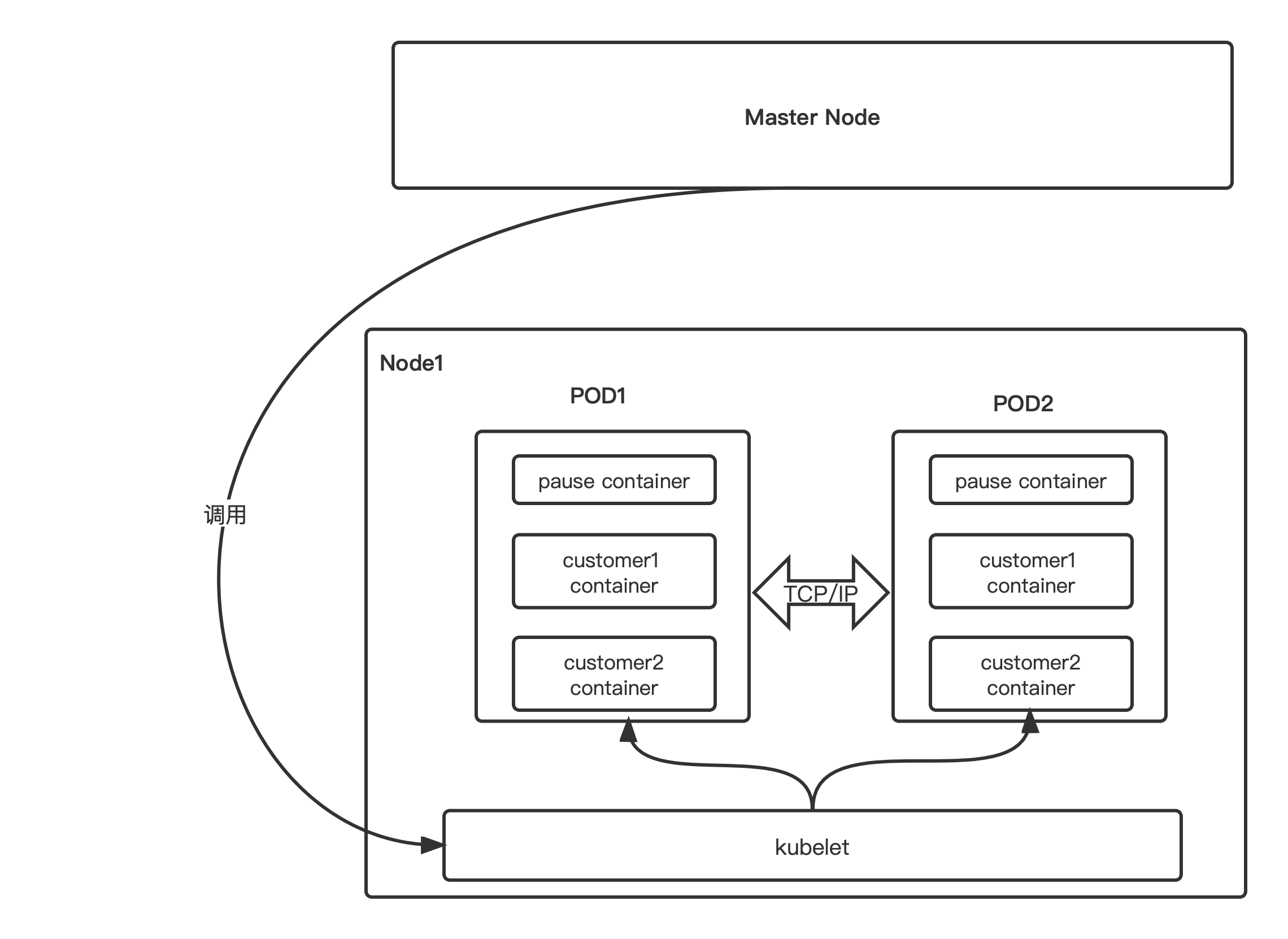
3.3 Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod(就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。 Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。 Pod 所建模的是特定于应用的 “逻辑主机”,其中包含一个或多个应用容器, 这些容器相对紧密地耦合在一起。 在非云环境中,在相同的物理机或虚拟机上运行的应用类似于在同一逻辑主机上运行的云应用。
master,node,pod,container 关系如下:
3.3 Label
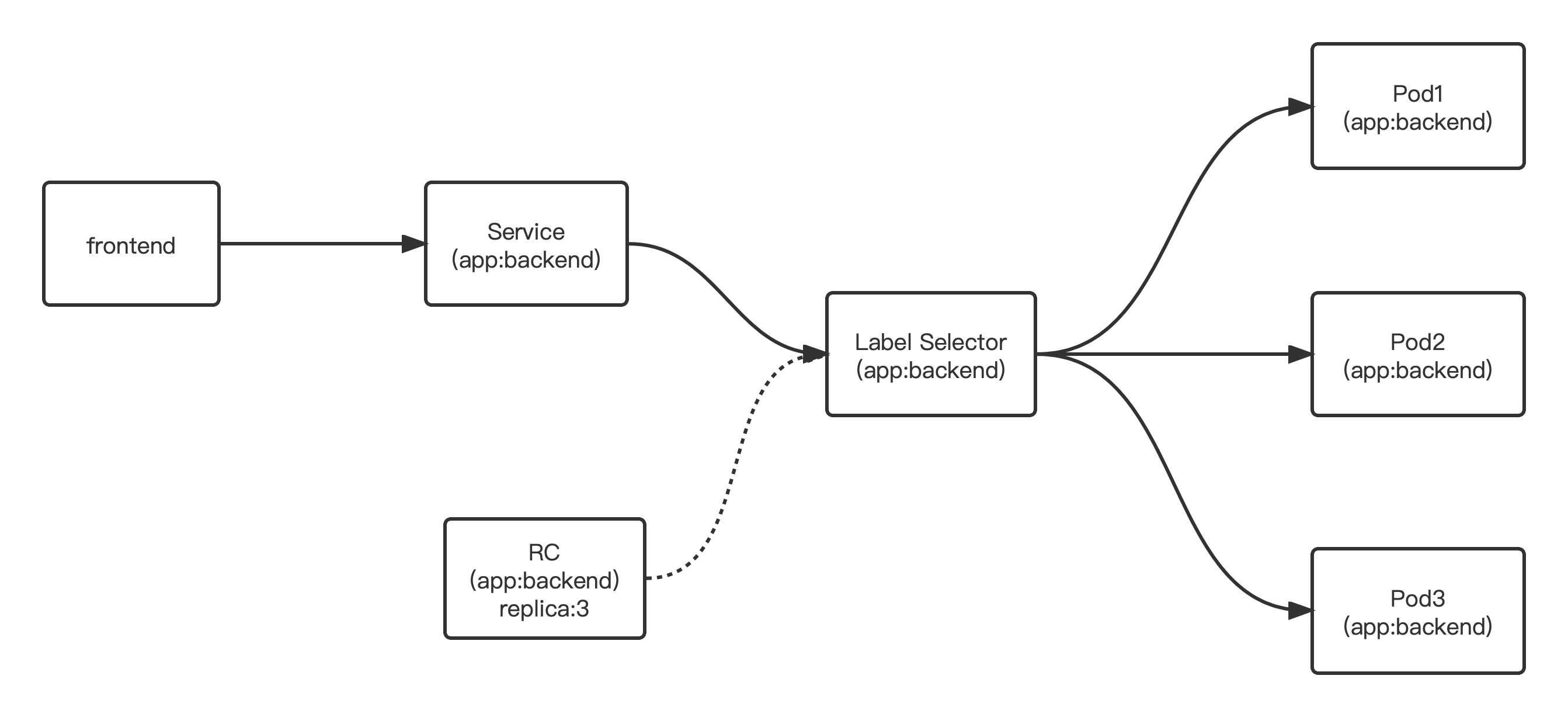
Label 是 Kubernetes 系统中另外一个核心概念。一个 Label 是一个 key=value 的键值对,其中 key 与 value 由用户自己指定。Label 可以附加到各种资源对象上, 例如Node、Pod、Service、RC 等,一个资源对象可以定义任意数量的 Label,同一个 Label 也可以被添加到任意数量的资源对象上去, Label 通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。 我们可以通过给指定的资源对象捆绑一个或多个不同的 Label 来实现多维度的资源分组管理功能, 以便于灵活、方便地进行资源分配、调度、配置、部署等管理工作。例如∶ 部署不同版本的应用到不同的环境中; 或者监控和分析应用(日志记录、监控、告警)等。一些常用的 Label 示例如下。
- 版本标签∶”release”∶”stable”,”release”∶”canary”…
- 环境标签∶”environment”∶”dev”,”environment”∶”qa”,”environment”∶”production”
- 架构标签∶”tier”∶”frontend”,”tier”∶”backend”,”tier”∶”middleware”
- 分区标签∶”partition”∶”customerA”,”partition”∶”customerB”
- 质量管控标签”track”∶”daily”,”track”∶”weekly”
Label 相当于我们熟悉的“标签”,给某个资源对象定义一个 Label,就相当于给它打了一个标签, 随后可以通过 Label Selector(标签选择器)查询和筛选拥有某些 Label 的资源对象, Kubernetes 通过这种方式实现了类似 SQL的简单又通用的对象查询机制。
Label Selector 在Kubernetes 中的重要使用场景有以下几处。
- kube-controller 进程通过资源对象 RC 上定义的 Label Selector 来筛选要监控的 Pod 副本 的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程。
- kube-proxy 进程通过 Service 的 Label Selector 来选择对应的 Pod,自动建立起每个 Service 到对应Pod的请求转发路由表,从而实现 Service 的智能负载均衡机制。
- 通过对某些 Node 定义特定的 Label ,并且在 Pod 定义文件中使用NodeSelector这种标 签调度策略,kube-scheduler 进程可以实现 Pod “定向调度”的特性。
3.5 Replication Controller
RC 是 Kubernetes 系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种 Pod 的副本数量在任意时刻都符合某个预期值,所以 RC 的定义包括如下几个部分。
- Pod期待的副本数(replicas)。
- 用于筛选目标 Pod 的 Label Selector。
- 当Pod 的副本数量小于预期数量的时候,用于创建新 Pod 的 Pod 模板(template)。
这个只了解下,重点介绍 RC 增强版 Deployment
3.6 Deployment
Deployment相对于RC的一个最大升级是我们可以随时知道当前Pod”部署”的进度。 实际上由于一个 Pod 的创建、调度、绑定节点及在目标 Node 上启动对应的容器这一完整过程需要一定的时间, 所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的”部署过程”导致的最终状态。 Deployment的典型使用场景有以下几个。
- 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。
- 检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值)。
- 更新Deployment 以创建新的Pod(比如镜像升级)。
- 如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
apiVersion: extensions/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat.
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
3.7 Horizontal Pod Autoscaler ( HPA )
Horizontal Pod Autoscaling 简称 HPA,意思是 Pod 横向自动扩容,与之前的 RC、Deployment 一样,也属于一种 Kubernetes 资源对象。 通过追踪分析RC控制的所有目标 Pod 的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是 HPA 的实现原理。 当前,HPA可以有以下两种方式作为Pod负载的度量指标。
- CPUUtilizationPercentage。O
- 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数(TPS或QPS)。
3.8 Service
3.8.1 概述
Service也是Kubernetes里的最核心的资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个”微服务”,
之前我们所说的Pod、RC等资源对象其实都是为这节所说的“服务”————Kubernetes Service做“嫁衣”的。
1
2
3
4
5
6
7
8
9
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
ports:
- port: 8080
selector:
tier: frontend
3.8.2 服务发现
每个 Service 分配了全局唯一的虚拟 IP,我们称它为 ClusterId 它有效的解决了服务发现机制,在它的有效期内 IP 是不变的。,并且拥有全局唯一的名字,在k8s内部,可以直接 用 http://${serviceName}.${namespace} 来访问服务。服务名称和IP绑定机制通过 k8s 拥有自己的 DNS 解决机制,这个后续见
3.8.3 外部访问
为了更加深入地理解和掌握 Kubernetes,我们需要弄明白 Kubernetes 里的“三种 IP ”这个关键问题,这三种 IP 分别如下:
- Node IP∶Node 节点的 IP 地址。
- Pod IP∶Pod 的 IP 地址。
- Cluster IP∶Service 的 IP 地址。
首先,Node IP 是 Kubernetes 集群中每个节点的物理网卡的 IP 地址,这是一个真实存在的物理网络, 所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个 Kubernetes 集群。 这也表明了 Kubernetes 集群之外的节点访问 Kubernetes 集群之内的某个节点或者 TCP/IP 服务的时候,必须要通过 Node IP进行通信。
其次,Pod IP 是每个 Pod 的 IP 地址,它是 Docker Engine 根据 docker0 网桥的 IP 地址段进行分配的,通常是一个虚拟的二层网络, 前面我们说过,Kubernetes 要求位于不同 Node 上的 Pod 能够彼此直接通信,所以 Kubernetes 里一个 Pod 里的容器访问另外一个 Pod 里的容器, 就是通过 PodIP 所在的虚拟二层网络进行通信的,而真实的 TCP/IP 流量则是通过 NodeIP 所在的物理网卡流出的。
最后,我们说说 Service 的 Cluster IP,它也是一个虚拟的 IP,但更像是一个”伪造”的 IP 网络,原因有以下几点:
- Cluster IP 仅仅作用于 Kubernetes Service 这个对象,并由 Kubernetes 管理和分配IP地 址(来源于 Cluster IP 地址池)。
- Cluster IP 无法被 Ping,因为没有一个”实体网络对象”来响应。
- Cluster IP 只能结合 Service Port 组成一个具体的通信端口,单独的 Cluster IP不具备 TCP/IP 通信的基础,并且它们属于 Kubernetes 集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。
- 在 Kubernetes 集群之内,Node IP网、Pod IP 网与 Cluster IP网之间的通信,采用的是 Kubernetes 自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP 路由有很大的不同。
3.9 Volume
Volume 是 Pod 中能够被多个容器访问的共享目录。Kubernetes 的 Volume 概念、用途和目的与 Docker 的 Volume 比较类似,但两者不能等价。首先,Kubernetes 中的 Volume 定义在 Pod 上,然后被一个 Pod 里的多个容器挂载到具体的文件目录下;其次,Kubernetes 中的 Volume 与 Pod 的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时, Volume中的数据也不会丢失。最后,Kubernetes 支持多种类型的 Volume,例如 GlusterFS、Ceph 等先进的分布式文件系统。 Volume 的使用也比较简单,在大多数情况下,我们先在 Pod 上声明一个 Volume ,然后在容器里引用该 Volume 并 Mount 到容器里的某个目录上。 举例来说,我们要给之前的 Tomcat Pod 增加一个名字为 dataVol 的 Volume,并且 Mount 到容器的 /mydata-data 目录上, 则只要对 Pod 的定义文件做如下修正即可(注意黑体字部分)∶
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
volumes:
- name: datavol
emptyDir: {}
containers:
- name: tomcat-demo
image: tomcat
volumeMounts:
- mountPath:/mydata-data
name: datavol
imagePullPolicy: IfNotPresent
3.10 Persistent Volume ( PV ) & PersistentVolumeClaim ( PVC )
PersistentVolumeClaim(持久卷声明,简称PVC)是用户的一种存储请求。它和 Pod 类似,Pod 消耗 Node 资源,而 PVC 消耗 PV 资源。Pod 能够请求特定的资源(如 CPU 和内存)。 PVC 能够请求指定的大小和访问的模式(可以被映射为一次读写或者多次只读)。 PVC 与 PV 的绑定是一对一的映射。没找到匹配的 PV,那么 PVC 会无限期得处于 unbound 未绑定状态。
PV描述文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: v1
kind: PersistentVolume
metadata:
name: myclaim
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
主要了解 AccessModes 具有如下可选值:
- ReadWriteOnce:可以被一个node读写。缩写为 RWO。
- ReadOnlyMany:可以被多个node读取。缩写为 ROX。
- ReadWriteMany:可以摆多个node读写。缩写为 RWX。
在Pod中使用PVC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
3.11 Namespace
Namespace(命名空间)是Kubernetes系统中的另一个非常重要的概念,Namespace 在很多情况下用于实现多租户的资源隔离。 Namespace 通过将集群内部的资源对象”分配”到不同的 Namespace 中,形成逻辑上分组的不同项目、小组或用户组, 便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
参考文献
